Key Takeaway
Strong T661 narratives share three qualities: specific numbers tied to technical constraints, a hypothesis-test-result structure for every investigation phase, and zero business language in the technical fields.
The T661 has a documentation problem. CRA’s T4088 guide explains what each field requires, but it never shows you what a good answer looks like. For technical leads filing for the first time, that gap is expensive. Claims that describe the right work the wrong way get denied or heavily reduced.
This post fills that gap. The scenario is fictional but realistic: a Canadian fintech startup with 12 developers, filing their first SR&ED claim for a machine learning-based fraud detection system built during fiscal year 2025. We’ll walk through Part 2 of the T661 in full, covering the project title, Section B’s three narrative fields, and the supporting Section C details.
The Scenario
Company: Veltro Financial Inc., a Series A fintech startup based in Toronto. Headcount: 52 employees, 12 software developers. Product: A B2B payment infrastructure platform for Canadian mid-market merchants. Fiscal year: January 1 to December 31, 2025. SR&ED project: Development of an ML-based transaction fraud detection system designed to reduce false positives without increasing fraud pass-through.
The fraud detection work occupied four developers for approximately seven months. Veltro’s CTO is completing Part 2 of the T661 for this project.

What Goes in Part 2, Section A?
This section is administrative, but the project title matters. CRA reviewers use it to understand scope before reading the narratives. It should be technical and specific.
Project Title:
Development of a probabilistic fraud detection system using gradient-boosted ensemble models with adaptive threshold calibration for real-time payment authorization
That title does several things. It names the technique (gradient-boosted ensemble), the novel element (adaptive threshold calibration), the application context (real-time payment authorization), and the method class (probabilistic). A reviewer can immediately see this is ML engineering work, not routine integration.
Compare that to a weaker version: “Fraud Detection Feature Development.” That title signals a product feature, not a research investigation. It sets the wrong frame before the reviewer reads a single word of the narrative.
Field of science code: For ML-based software, the appropriate code is typically 2.3 (Computer Science) or 2.2 (Information and Communication Technology), depending on whether the work is more theoretical or applied. Veltro would select 2.3.
How Do You Write Line 242 (Technological Uncertainty)?
CRA requires you to describe why the technical outcome was not knowable at the start. Why couldn’t a qualified practitioner have predicted the solution without original investigation? 350 words max.
What Veltro writes:
Veltro’s transaction dataset exhibits a class imbalance of approximately 1:400 (fraud to legitimate transactions). Standard gradient-boosted classifiers trained on this distribution produce models that minimize aggregate loss by predicting the majority class, achieving acceptable accuracy metrics while missing the fraud cases that represent disproportionate financial and regulatory risk.
The central uncertainty was whether adaptive threshold calibration — dynamically adjusting the decision boundary at inference time based on real-time feature drift — could reduce false positive rates on legitimate high-value transactions without increasing fraud pass-through rates at our authorization volumes (approximately 180,000 transactions per day). No published methodology addressed this specific interaction at production authorization latency constraints (sub-150ms end-to-end).
Two secondary uncertainties emerged during investigation. First, whether feature drift in our merchant category distribution — driven by seasonal transaction patterns — would destabilize calibrated thresholds over weekly inference cycles, requiring retraining frequencies incompatible with production deployment. Second, whether the ensemble architecture could maintain calibration stability under concurrent write loads when transaction velocity exceeded 1,200 requests per second, a load profile absent from the academic literature we reviewed.
Published solutions for imbalanced classification (SMOTE, cost-sensitive learning, threshold moving) were evaluated and found insufficient at our operating constraints. Applying these known methods addressed the class imbalance in controlled testing environments but failed to generalize to our production feature distribution, where merchant category mix, time-of-day patterns, and authorization velocity interact in ways not represented in available benchmark datasets.
Why this works: each paragraph addresses one of CRA’s three requirements for genuine technological uncertainty. The uncertainty existed at project start, it was beyond what known methods could resolve, and the investigators couldn’t determine the outcome without original investigation. The text is specific to Veltro’s operating context (180,000 transactions per day, sub-150ms latency, 1:400 class imbalance). It’s not generic.
How Do You Write Line 244 (Work Performed)?
This is the systematic investigation record. CRA’s five-question test from Northwest Hydraulic Consultants runs through this field. 700 words max.
Structure it chronologically. Each hypothesis-test-result cycle is one unit of systematic investigation.
What Veltro writes:
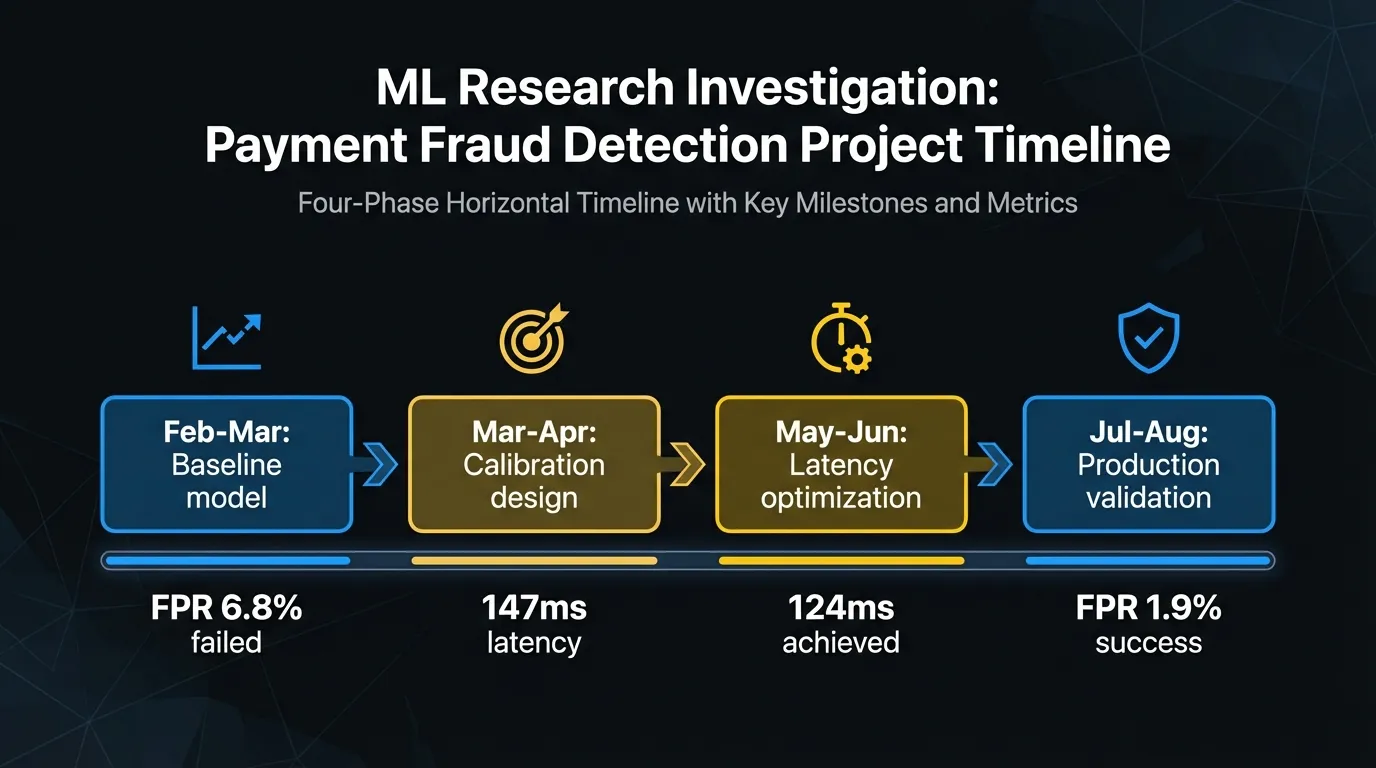
Phase 1: Baseline model construction and failure analysis (February to March 2025)
We trained a baseline XGBoost classifier on 14 months of historical transaction data (23.4M transactions, fraud prevalence 0.24%). Initial performance on held-out test data showed AUC-PR of 0.71 and a false positive rate (FPR) of 6.8% at the 0.5 decision threshold — unacceptably high for production use, where false positives trigger friction with high-value merchant clients. Our hypothesis was that threshold optimization at inference time would reduce FPR below 2.0% without material impact on fraud recall. Threshold grid search across [0.3, 0.7] reduced FPR to 3.2% but increased fraud pass-through by 18%. This confirmed that static threshold optimization was insufficient for our class distribution and that dynamic calibration during inference would be required.
Phase 2: Adaptive calibration architecture design (March to April 2025)
We investigated two calibration approaches: isotonic regression applied post-hoc to model outputs, and a Platt scaling variant modified to accept real-time feature drift signals as calibration inputs. The hypothesis was that Platt scaling extended with drift inputs would maintain calibration stability across merchant category shifts without requiring full model retraining. Isotonic regression produced better static calibration (Brier score reduction from 0.048 to 0.031) but showed degradation during periods of high merchant category shift (measured weekly via Jensen-Shannon divergence). The modified Platt approach maintained calibration through three simulated seasonal shift scenarios but introduced 22ms of additional inference latency — pushing our P99 authorization time to 147ms, within the 150ms constraint but with no headroom for network variance.
Phase 3: Latency optimization and concurrent write testing (May to June 2025)
To recover latency headroom, we investigated parallelizing the calibration computation against the base model inference rather than running them sequentially. Hypothesis: async calibration with a fallback to last-known-good calibration state would reduce P99 latency below 130ms and maintain calibration freshness within one minute of drift. We implemented this architecture and stress-tested at 1,400 requests per second sustained over 90-minute windows. P99 latency fell to 118ms under normal load but increased to 161ms during garbage collection pauses in our JVM runtime, exceeding the constraint. We resolved this by pre-allocating calibration state objects and implementing explicit GC tuning, which brought P99 latency to 124ms under the same load profile.
Phase 4: Production validation (July to August 2025)
We deployed the calibration system in shadow mode alongside the existing rule-based fraud filter for 45 days, processing live transactions without affecting authorization decisions. Results: FPR on high-value transactions (over $500) fell from 6.8% to 1.9%. Fraud recall held at 0.941 vs. the baseline’s 0.938. No calibration instability events were observed during two seasonal merchant category shifts (back-to-school and pre-Thanksgiving). These results validated the approach and the system was deployed to production in September 2025.
How Do You Write Line 246 (Technological Advancement)?
This field describes what new knowledge exists as a result of the work. The key word is “knowledge,” not “product.” 350 words max.
What Veltro writes:
This project produced three areas of new technical knowledge.
First, we established that Platt scaling can be extended with real-time drift signals to maintain calibration stability through merchant category shifts without full model retraining, provided the drift signal is computed on a sliding window of no more than 500 recent transactions. This finding is specific to high-imbalance classification problems with non-stationary feature distributions in payment authorization contexts and is not documented in published calibration literature we reviewed.
Second, we characterized the latency-accuracy tradeoff of async calibration in JVM-hosted inference services under high-concurrency write loads. Our experiments demonstrated that pre-allocated calibration state combined with explicit minor GC tuning eliminates the P99 latency variance introduced by JVM garbage collection in concurrent calibration scenarios — a finding specific to our concurrency and latency profile.
Third, we quantified the minimum retraining frequency required to maintain FPR targets through documented seasonal transaction shifts in Canadian mid-market merchant populations. Our shadow deployment data shows that weekly recalibration is sufficient to maintain FPR below 2.0% through shifts up to 0.14 Jensen-Shannon divergence; larger shifts require retraining. This threshold was not predictable from existing literature on payment fraud drift and required direct empirical investigation.
These findings extend the team’s understanding of adaptive calibration for production ML inference beyond the baseline knowledge available at project start.
What Goes in Part 2, Section C?
Technical personnel (Line 260):
Sarah Chen, Lead ML Engineer — designed and implemented the calibration architecture. James Okafor, Senior Backend Engineer — led latency optimization and JVM profiling. Priya Nair, Data Engineer — built shadow deployment infrastructure and maintained production data pipelines.
Documentation available (Line 270):
Git commit history (GitHub); pull request review logs with technical discussion threads; sprint planning documents (Linear); architecture decision records (Confluence, 14 documents); model evaluation reports (Weights & Biases experiment tracking, 63 runs); load testing results (Grafana dashboards, exported); shadow deployment daily performance reports.
What Goes in Part 3 (Expenditures)?
Veltro’s claim would include:
- Salaries (proxy method): Four developers, seven months at an average annual salary of approximately $120K. Under the proxy method, overhead is calculated as 55% of the eligible salary.
- Subcontractor costs: An external ML consultant engaged for six weeks to advise on calibration architecture. Requires a signed contract, invoices, and a statement of the qualifying work performed.
- No capital expenditures: Cloud compute costs for training runs are generally not eligible under SR&ED.
What Makes These Narratives Work?
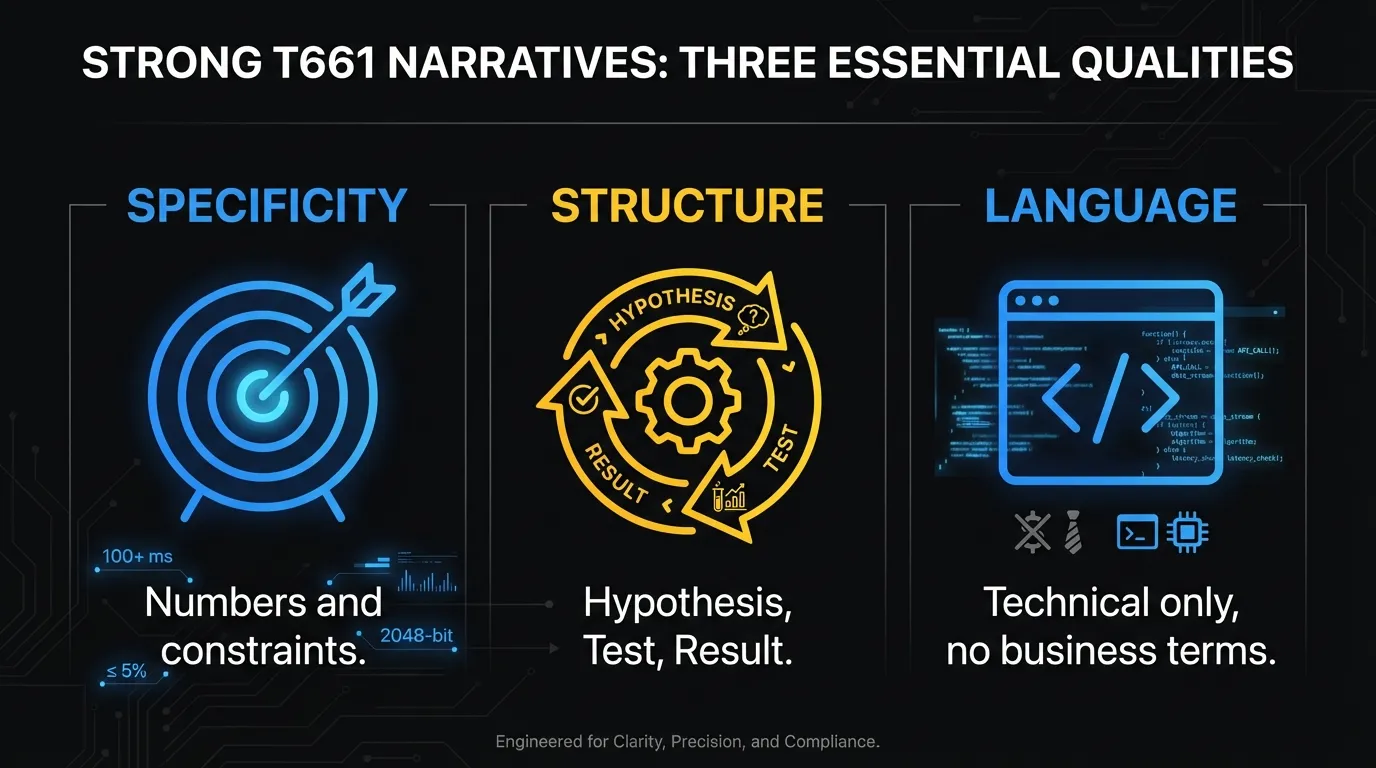
Three things separate the Veltro examples from the narratives that get reduced or denied.
Specificity. Every claim is tied to a number, a constraint, a specific outcome. AUC-PR of 0.71. Sub-150ms authorization latency. 1:400 class imbalance. Specificity is what proves the work actually happened and that the team understood what they were doing.
The hypothesis-test-result structure. Every phase in Line 244 follows the same pattern: what the team expected, what they did to test it, what they found. This structure maps directly onto CRA’s five-question systematic investigation test.
Technical language, no business language. None of Veltro’s narratives mention customers, revenue, competitive position, or product goals. Every sentence describes a technical fact.
Why Is This Hard to Scale?
Writing one strong T661 narrative is a contained exercise. The problem most engineering teams face is that they have multiple qualifying projects across a fiscal year, and producing this level of technical depth for each one requires time and recall that’s hard to reconstruct months after the fact.
Chrono R&D connects to your git history, issue tracker, and project management tools, then produces the Part 2 narratives automatically from what your team already documented during the project.
Frequently Asked Questions
Can I use this T661 example directly for my company’s claim?
No. CRA reviewers are experienced with generic narratives. The Veltro example works because every detail is specific to Veltro’s operating context: their transaction volume, their latency constraint, their class imbalance ratio. Your narratives need to reflect your actual technical work with the same level of specificity.
What happens if my T661 narratives are too vague?
CRA may reduce your claim or request additional technical information. In a review, a reviewer with engineering expertise will test whether your narrative actually describes a genuine technological uncertainty. Vague narratives that don’t tie to specific constraints are the primary reason software company claims get reduced.
Does the proxy method cover cloud compute costs?
No. The proxy method applies 55% overhead to eligible salary costs. It doesn’t cover cloud compute for training runs. Cloud infrastructure costs are generally not eligible as SR&ED expenditures.
Ready to produce T661 narratives without the manual effort? Contact us to see how Chrono R&D generates Part 2 documentation directly from your existing development records.