Point clé
Les bons narratifs T661 partagent trois caractéristiques: des chiffres précis liés à des contraintes techniques, une structure hypothèse-test-résultat pour chaque phase d'investigation, et zéro langage commercial dans les champs techniques.
Le formulaire T661 a un problème de documentation. Le guide T4088 de l’ARC explique ce que chaque champ requiert, mais ne montre jamais à quoi ressemble une bonne réponse. Pour les responsables techniques qui produisent leur première demande de RS&DE, cet écart coûte cher. Les demandes qui décrivent le bon travail de la mauvaise façon sont refusées ou fortement réduites.
Cet article comble cette lacune. Le scénario est fictif mais réaliste: une startup fintech canadienne comptant 12 développeurs, qui produit sa première demande RS&DE pour un système de détection de fraude basé sur l’apprentissage automatique construit au cours de l’exercice 2025. Nous parcourons la Partie 2 du T661 au complet, couvrant le titre du projet, les trois champs narratifs de la Section B et les détails de la Section C.
Le scénario
Entreprise: Veltro Financial Inc., une startup fintech de série A basée à Toronto. Effectifs: 52 employés, 12 développeurs logiciels. Produit: Une plateforme d’infrastructure de paiement B2B pour les marchands canadiens du marché intermédiaire. Exercice financier: 1er janvier au 31 décembre 2025. Projet RS&DE: Développement d’un système de détection de fraude par transactions basé sur le ML, conçu pour réduire les faux positifs sans augmenter le taux de fraude non détectée.
Le travail de détection de fraude a mobilisé quatre développeurs pendant environ sept mois. Le CTO de Veltro complète la Partie 2 du T661 pour ce projet.

Que contient la Partie 2, Section A?
Cette section est administrative, mais le titre du projet compte. Les réviseurs de l’ARC l’utilisent pour comprendre la portée avant de lire les narratifs. Il doit être technique et précis.
Titre du projet:
Development of a probabilistic fraud detection system using gradient-boosted ensemble models with adaptive threshold calibration for real-time payment authorization
Ce titre fait plusieurs choses. Il nomme la technique (gradient-boosted ensemble), l’élément novateur (calibration adaptative des seuils), le contexte d’application (autorisation de paiement en temps réel) et la classe de méthodes (probabiliste). Un réviseur voit immédiatement qu’il s’agit d’ingénierie ML, pas d’une intégration ordinaire.
Comparez avec une version plus faible: “Fraud Detection Feature Development.” Ce titre signale une fonctionnalité produit, pas une investigation de recherche. Il crée le mauvais cadre avant même que le réviseur lise un seul mot du narratif.
Code du domaine scientifique: Pour les logiciels basés sur le ML, le code approprié est généralement 2.3 (Informatique) ou 2.2 (Technologies de l’information et des communications), selon que les travaux sont plus théoriques ou appliqués. Veltro choisirait 2.3.
Comment rédiger la Ligne 242 (Incertitude technologique)?
L’ARC exige que vous décriviez pourquoi le résultat technique n’était pas connaissable au départ. Pourquoi un praticien qualifié n’aurait-il pas pu prédire la solution sans investigation originale? Maximum 350 mots.
Ce que Veltro écrit:
Veltro’s transaction dataset exhibits a class imbalance of approximately 1:400 (fraud to legitimate transactions). Standard gradient-boosted classifiers trained on this distribution produce models that minimize aggregate loss by predicting the majority class, achieving acceptable accuracy metrics while missing the fraud cases that represent disproportionate financial and regulatory risk.
The central uncertainty was whether adaptive threshold calibration — dynamically adjusting the decision boundary at inference time based on real-time feature drift — could reduce false positive rates on legitimate high-value transactions without increasing fraud pass-through rates at our authorization volumes (approximately 180,000 transactions per day). No published methodology addressed this specific interaction at production authorization latency constraints (sub-150ms end-to-end).
Two secondary uncertainties emerged during investigation. First, whether feature drift in our merchant category distribution — driven by seasonal transaction patterns — would destabilize calibrated thresholds over weekly inference cycles, requiring retraining frequencies incompatible with production deployment. Second, whether the ensemble architecture could maintain calibration stability under concurrent write loads when transaction velocity exceeded 1,200 requests per second, a load profile absent from the academic literature we reviewed.
Published solutions for imbalanced classification (SMOTE, cost-sensitive learning, threshold moving) were evaluated and found insufficient at our operating constraints. Applying these known methods addressed the class imbalance in controlled testing environments but failed to generalize to our production feature distribution, where merchant category mix, time-of-day patterns, and authorization velocity interact in ways not represented in available benchmark datasets.
Pourquoi ça fonctionne: chaque paragraphe répond à l’une des trois exigences de l’ARC pour une véritable incertitude technologique. L’incertitude existait dès le début du projet, elle dépassait ce que les méthodes connues pouvaient résoudre, et les investigateurs ne pouvaient pas déterminer le résultat sans investigation originale. Le texte est spécifique au contexte opérationnel de Veltro (180 000 transactions par jour, latence sous 150ms, déséquilibre de classes 1:400). Ce n’est pas générique.
Comment rédiger la Ligne 244 (Travaux effectués)?
C’est l’enregistrement de l’investigation systématique. Le test en cinq questions de l’ARC tiré de la décision Northwest Hydraulic Consultants s’applique à ce champ. Maximum 700 mots.
Structurez-le chronologiquement. Chaque cycle hypothèse-test-résultat constitue une unité d’investigation systématique.
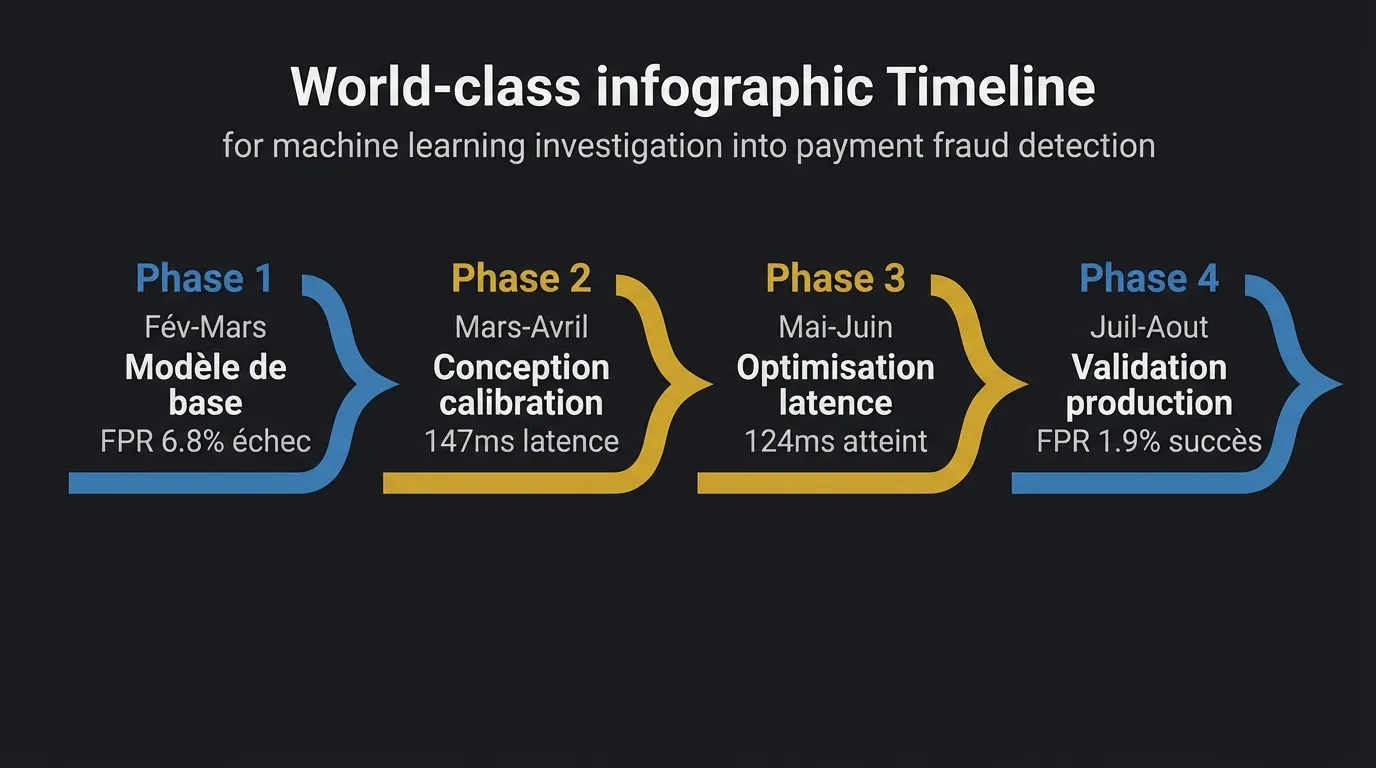
Ce que Veltro écrit:
Phase 1: Baseline model construction and failure analysis (February to March 2025)
We trained a baseline XGBoost classifier on 14 months of historical transaction data (23.4M transactions, fraud prevalence 0.24%). Initial performance on held-out test data showed AUC-PR of 0.71 and a false positive rate (FPR) of 6.8% at the 0.5 decision threshold — unacceptably high for production use, where false positives trigger friction with high-value merchant clients. Our hypothesis was that threshold optimization at inference time would reduce FPR below 2.0% without material impact on fraud recall. Threshold grid search across [0.3, 0.7] reduced FPR to 3.2% but increased fraud pass-through by 18%. This confirmed that static threshold optimization was insufficient for our class distribution and that dynamic calibration during inference would be required.
Phase 2: Adaptive calibration architecture design (March to April 2025)
We investigated two calibration approaches: isotonic regression applied post-hoc to model outputs, and a Platt scaling variant modified to accept real-time feature drift signals as calibration inputs. The hypothesis was that Platt scaling extended with drift inputs would maintain calibration stability across merchant category shifts without requiring full model retraining. Isotonic regression produced better static calibration (Brier score reduction from 0.048 to 0.031) but showed degradation during periods of high merchant category shift (measured weekly via Jensen-Shannon divergence). The modified Platt approach maintained calibration through three simulated seasonal shift scenarios but introduced 22ms of additional inference latency — pushing our P99 authorization time to 147ms, within the 150ms constraint but with no headroom for network variance.
Phase 3: Latency optimization and concurrent write testing (May to June 2025)
To recover latency headroom, we investigated parallelizing the calibration computation against the base model inference rather than running them sequentially. Hypothesis: async calibration with a fallback to last-known-good calibration state would reduce P99 latency below 130ms and maintain calibration freshness within one minute of drift. We implemented this architecture and stress-tested at 1,400 requests per second sustained over 90-minute windows. P99 latency fell to 118ms under normal load but increased to 161ms during garbage collection pauses in our JVM runtime, exceeding the constraint. We resolved this by pre-allocating calibration state objects and implementing explicit GC tuning, which brought P99 latency to 124ms under the same load profile.
Phase 4: Production validation (July to August 2025)
We deployed the calibration system in shadow mode alongside the existing rule-based fraud filter for 45 days, processing live transactions without affecting authorization decisions. Results: FPR on high-value transactions (over $500) fell from 6.8% to 1.9%. Fraud recall held at 0.941 vs. the baseline’s 0.938. No calibration instability events were observed during two seasonal merchant category shifts (back-to-school and pre-Thanksgiving). These results validated the approach and the system was deployed to production in September 2025.
Comment rédiger la Ligne 246 (Avancement technologique)?
Ce champ décrit les nouvelles connaissances qui existent grâce aux travaux. Le mot clé est “connaissances,” pas “produit.” Maximum 350 mots.
Ce que Veltro écrit:
This project produced three areas of new technical knowledge.
First, we established that Platt scaling can be extended with real-time drift signals to maintain calibration stability through merchant category shifts without full model retraining, provided the drift signal is computed on a sliding window of no more than 500 recent transactions. This finding is specific to high-imbalance classification problems with non-stationary feature distributions in payment authorization contexts and is not documented in published calibration literature we reviewed.
Second, we characterized the latency-accuracy tradeoff of async calibration in JVM-hosted inference services under high-concurrency write loads. Our experiments demonstrated that pre-allocated calibration state combined with explicit minor GC tuning eliminates the P99 latency variance introduced by JVM garbage collection in concurrent calibration scenarios — a finding specific to our concurrency and latency profile.
Third, we quantified the minimum retraining frequency required to maintain FPR targets through documented seasonal transaction shifts in Canadian mid-market merchant populations. Our shadow deployment data shows that weekly recalibration is sufficient to maintain FPR below 2.0% through shifts up to 0.14 Jensen-Shannon divergence; larger shifts require retraining. This threshold was not predictable from existing literature on payment fraud drift and required direct empirical investigation.
These findings extend the team’s understanding of adaptive calibration for production ML inference beyond the baseline knowledge available at project start.
Que contient la Partie 2, Section C?
Personnel technique (Ligne 260):
Sarah Chen, Lead ML Engineer — a conçu et implémenté l’architecture de calibration. James Okafor, Senior Backend Engineer — a dirigé l’optimisation de la latence et le profilage JVM. Priya Nair, Data Engineer — a construit l’infrastructure de déploiement en mode shadow et maintenu les pipelines de données en production.
Documentation disponible (Ligne 270):
Historique des commits Git (GitHub); journaux de revue des pull requests avec fils de discussion techniques; documents de planification de sprint (Linear); enregistrements de décisions d’architecture (Confluence, 14 documents); rapports d’évaluation de modèles (suivi d’expériences Weights & Biases, 63 exécutions); résultats de tests de charge (tableaux de bord Grafana, exportés); rapports quotidiens de performance du déploiement en mode shadow.
Que contient la Partie 3 (Dépenses)?
La demande de Veltro inclurait:
- Salaires (méthode de substitution): Quatre développeurs, sept mois à un salaire annuel moyen d’environ 120 000 $. Avec la méthode de substitution, les frais généraux sont calculés à 55% du salaire admissible.
- Coûts des sous-traitants: Un consultant ML externe engagé pendant six semaines pour conseiller sur l’architecture de calibration. Requiert un contrat signé, des factures et un énoncé des travaux admissibles effectués.
- Aucune dépense en capital: Les coûts d’infrastructure infonuagique pour les exécutions d’entraînement ne sont généralement pas admissibles dans le cadre de la RS&DE.
Qu’est-ce qui distingue ces narratifs?
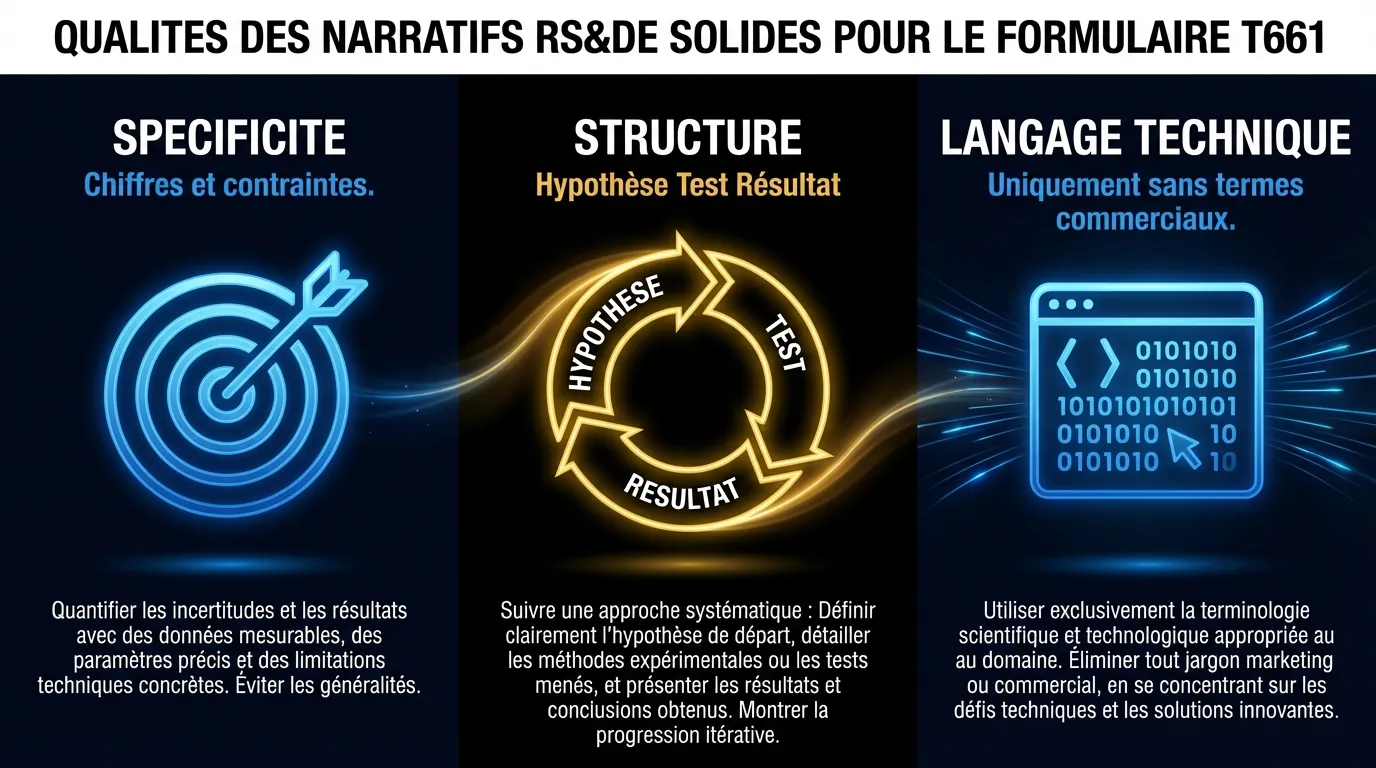
Trois éléments distinguent les exemples de Veltro des narratifs qui se font réduire ou refuser.
La spécificité. Chaque affirmation est liée à un chiffre, une contrainte, un résultat précis. AUC-PR de 0,71. Latence d’autorisation sous 150ms. Déséquilibre de classes de 1:400. La spécificité est ce qui prouve que le travail a réellement eu lieu et que l’équipe comprenait ce qu’elle faisait.
La structure hypothèse-test-résultat. Chaque phase de la Ligne 244 suit le même patron: ce que l’équipe anticipait, ce qu’elle a fait pour le tester, ce qu’elle a trouvé. Cette structure correspond directement au test d’investigation systématique en cinq questions de l’ARC.
Le langage technique, sans langage commercial. Aucun des narratifs de Veltro ne mentionne les clients, les revenus, la position concurrentielle ou les objectifs produit. Chaque phrase décrit un fait technique.
Pourquoi est-ce difficile à grande échelle?
Rédiger un bon narratif T661 est un exercice circonscrit. Le problème que la plupart des équipes techniques rencontrent, c’est qu’elles ont plusieurs projets admissibles sur un exercice financier, et produire ce niveau de profondeur technique pour chacun exige du temps et un rappel difficile à reconstruire des mois après coup.
Chrono R&D se connecte à votre historique Git, votre gestionnaire de tickets et vos outils de gestion de projets, puis produit les narratifs de la Partie 2 automatiquement à partir de ce que votre équipe a déjà documenté pendant le projet.
Foire aux questions
Puis-je utiliser cet exemple de T661 directement pour la demande de mon entreprise?
Non. Les réviseurs de l’ARC reconnaissent les narratifs génériques. L’exemple de Veltro fonctionne parce que chaque détail est spécifique au contexte opérationnel de Veltro: leur volume de transactions, leur contrainte de latence, leur ratio de déséquilibre de classes. Vos narratifs doivent refléter vos travaux techniques réels avec le même niveau de spécificité.
Que se passe-t-il si mes narratifs T661 sont trop vagues?
L’ARC peut réduire votre demande ou demander des informations techniques supplémentaires. Lors d’une révision, un réviseur ayant une expertise en ingénierie testera si votre narratif décrit réellement une véritable incertitude technologique. Les narratifs vagues qui ne sont pas liés à des contraintes spécifiques sont la principale raison pour laquelle les demandes des entreprises logicielles sont réduites.
La méthode de substitution couvre-t-elle les coûts d’infrastructure infonuagique?
Non. La méthode de substitution applique 55% de frais généraux aux coûts de salaire admissibles. Elle ne couvre pas l’infrastructure infonuagique pour les exécutions d’entraînement. Les coûts d’infrastructure en nuage ne sont généralement pas admissibles comme dépenses de RS&DE.
Prêt à produire des narratifs T661 sans l’effort manuel? Contactez-nous pour voir comment Chrono R&D génère la documentation de la Partie 2 directement à partir de vos enregistrements de développement existants.